
分布式一致性协议之Raft算法
前置知识
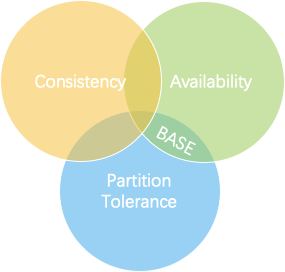
CAP理论
描述分布式一致性的三个维度,一个分布式系统只能满足三项中的两项而不可能满足全部三项。
一致性(Consistency)
每次读操作都能保证返回的是最新数据;在分布式系统中,如果能针对一个数据项的更新执行成功后,所有的请求都可以读到其最新的值,这样的系统就被认为具有严格的一致性。
可用性(Availablity)
任何一个没有发生故障的节点,会在合理的时间内返回一个正常的结果,也就是对于每一个请求总能够在有限时间内返回结果。
分区容忍性(Partition-torlerance)
当节点间出现网络分区,照样可以提供满足一致性和可用性的服务,除非整个网络环境都发生了故障。
BASE理论
CAP理论无法全部满足,为了指导工业实现,就需要降低标准,因此出现了BASE理论。
它的思想是:“即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性” 。
BASE理论有三项指标:
- 基本可用(Basically Available) :是指分布式系统在出现不可预知故障的时候,允许损失部分可用性:比如响应时间、功能降级等;
- 软状态( Soft State) :也称为弱状态,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点之间进行数据同步的过程存在延时;
- 最终一致性( Eventual Consistency) :强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达成一致的状态。

分区一致性
简要假设就是:主从库复制直接同步的是强一致性,主从库异步同步的是弱一致性,其中只保证数据最终一致的是最终一致性。
Paxos一致性算法
Paxos 算法是莱斯利·兰伯特于1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。
概念介绍:
- Proposal提案,即分布式系统的修改请求,可以表示为[提案编号N,提案内容value]
- Client用户,类似社会民众,负责提出建议
- Propser议员,类似基层人大代表,负责帮Client上交提案
- Acceptor投票者,类似全国人大代表,负责为提案投票,不同意比自己以前接收过的提案编号要小的提案,其他提案都同意,例如A以前给N号提案表决过,那么再收到小于等于N号的提案时就直接拒绝了
- Learner提案接受者,类似记录被通过提案的记录员,负责记录提案
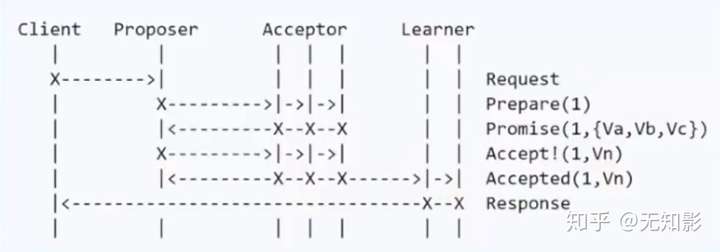
Basic Paxos 算法步骤:
- Propser准备一个N号提案
- Propser询问Acceptor中的多数派是否接收过N号的提案,如果都没有进入下一步,否则本提案不被考虑
- Acceptor开始表决,Acceptor无条件同意从未接收过的N号提案,达到多数派同意后,进入下一步
Learner记录提案
问题总览:
节点故障
若Proposer故障,没关系,再从集群中选出Proposer即可
若Acceptor故障,表决时能达到多数派也没问题
潜在问题-活锁
- 假设系统有多个Proposer,他们不断向Acceptor发出提案,还没等到上一个提案达到多数派下一个提案又来了,就会导致Acceptor放弃当前提案转向处理下一个提案,于是所有提案都别想通过了。
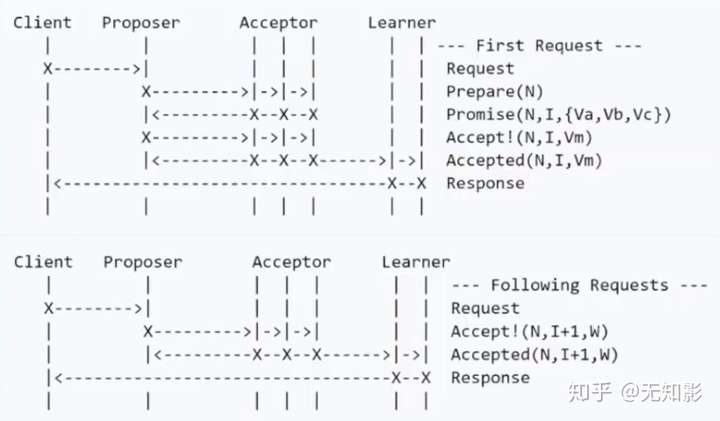
Multi Paxos算法
综上,对Basic Paxos的改进:整个系统只有一个Proposer,称之为Leader。
- 若集群中没有Leader,则在集群中选出一个节点并声明它为第M任Leader。
- 集群的Acceptor只表决最新的Leader发出的最新的提案
- 其他步骤和Basic Paxos相同
继续优化:Multi Paxos角色过多,对于计算机集群而言,可以将Proposer、Acceptor和Learner三者身份集中在一个节点上,此时只需要从集群中选出Proposer,其他节点都是Acceptor和Learner,这就是接下来要讨论的Raft算法。
Raft算法概述
Raft 是一种为了管理复制日志的一致性算法。
它提供了和 Paxos 算法相同的功能和性能,但是它的算法结构和 Paxos 不同,使得 Raft 算法更加容易理解并且更容易构建实际的系统。
概念介绍:
- Leader领导节点,负责发出提案
- Follower追随者节点,负责同意Leader发出的提案
- Candidate候选人,负责争夺Leader
Raft算法将一致性问题分解为两个的子问题,Leader选举和状态复制
Leader选举
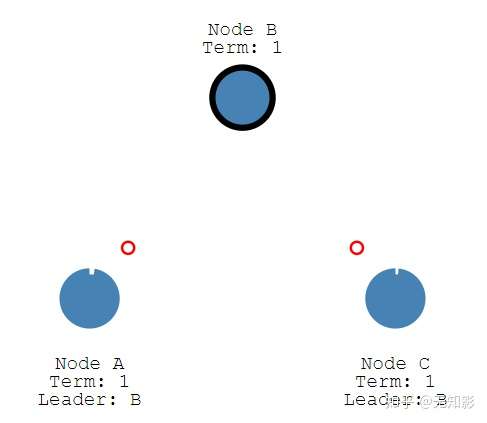
假设网络中有3个节点,最开始大家都是Follower节点,且Term(任期)为0。
- 每个Follower都有一个选举超时 ,这是是Follower等待成为Candidate的时间。选举超时随机设置在 150 毫秒和 300 毫秒之间。
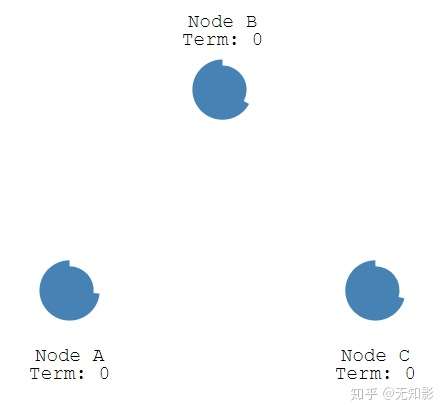
- 当选举超时时间到了,而仍然没有接收到Leader的心跳信息,Follower将声明自己是Candidate并参与Leader竞举,并且开始新的选举任期(Term+1)为自己投票,同时将消息发给其他节点来争取他们的投票。若其他节点长时间没有响应Candidate,将Term + 1且重新发送选举信息。
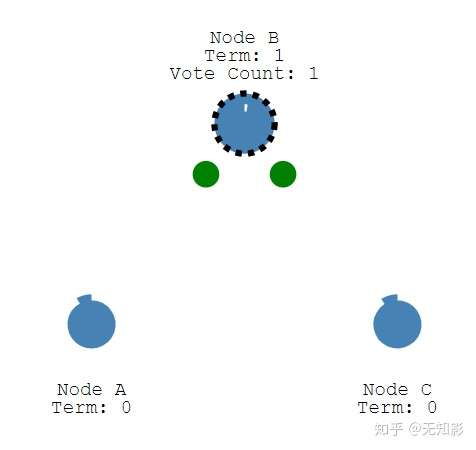
- 只要集群中其他节点在当前任期Term内还没投票,其他节点将给Candidate投票,并且重置选举超时。否则则认为当前的竞选消息不是最新的,拒绝为他投票。
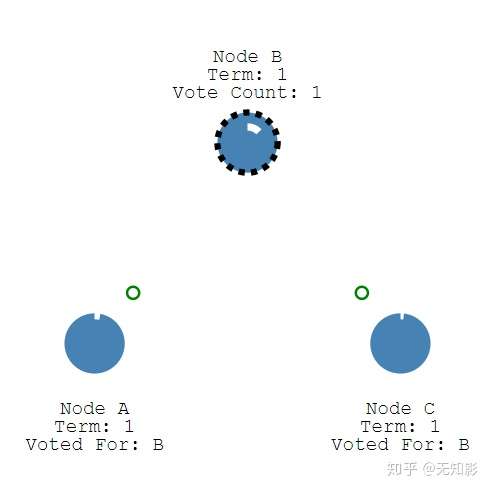
- 获得多数派支持的Candidate将成为第M任Leader(M任是最新的任期Term)
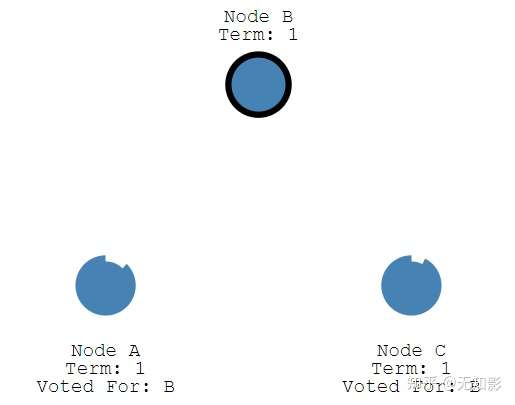
- 在任期内的Leader会不断发送心跳和追加条目给其他节点证明自己还活着,其他节点收到信息后追加日志信息并重置选举超时,回复Leader的信息。这个机制保证其他节点不会在Leader任期内参加Leader选举。
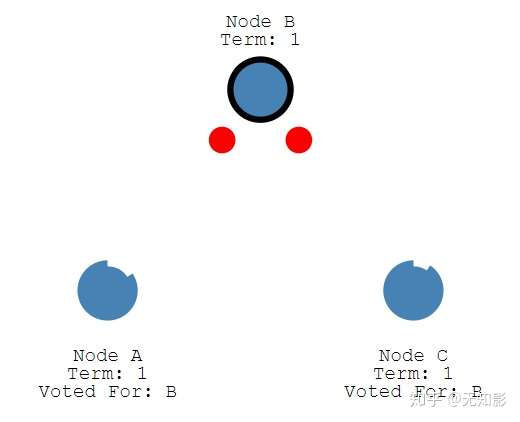
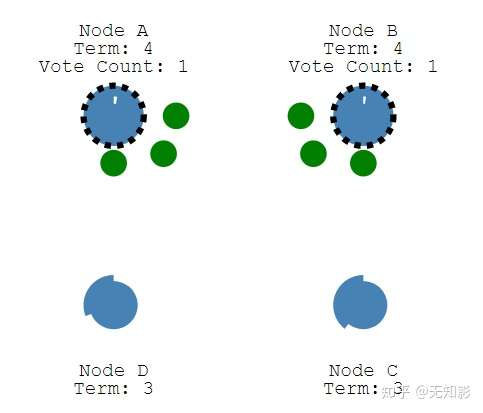
当Leader节点出现故障而导致Leader失联,没有接收到心跳的Follower节点将准备成为Candidate进入下一轮Leader选举
若出现两个Candidate同时选举并获得了相同的票数,那么这两个Candidate将随机推迟一段时间后再向其他节点发出投票请求,这保证了再次发送投票请求以后不冲突(上述的leader消息计时器时间随机,为的就是减少两个节点同时发送竞选请求,导致二分票,无法生成leader的情况)
三种状态的转换如图所示:

状态复制
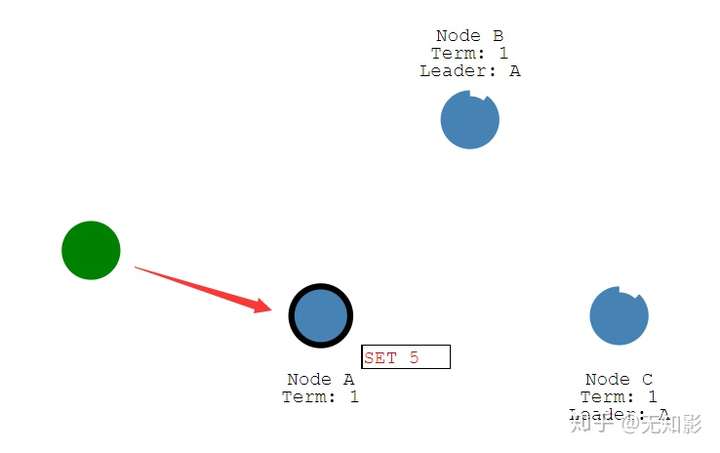
一旦我们选出了一个Leader,就需要将系统的所有更改复制到所有Follower节点。
Leader负责接收来自Client的提案请求(红色提案表示未确认),更改将被附加在leader的日志中。
此处需要注意的是,在如etcd中的实现里:client的消息是可以发送给Follower节点,Follower节点再向Leader节点报告。
- 提案(更改)内容将包含在Leader发出的下一个心跳中
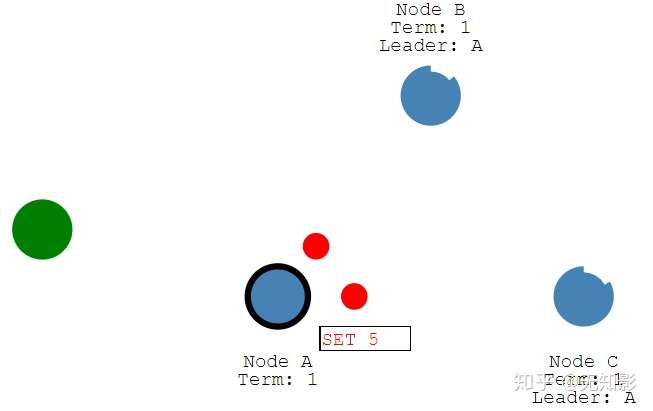
- Follower接收到心跳以后回复Leader的心跳
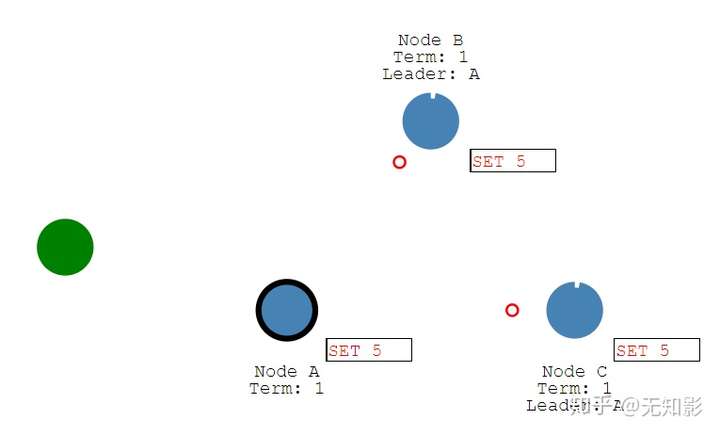
- Leader接收到多数派Follower的回复以后确认提案持久化到本地并回复Client
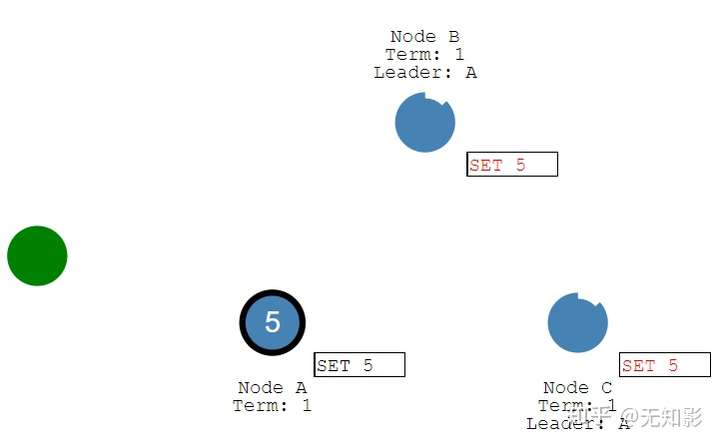
- Leader通知Follower节点确认提案/更改并写入自己的存储空间,随后所有的节点都拥有相同的数据
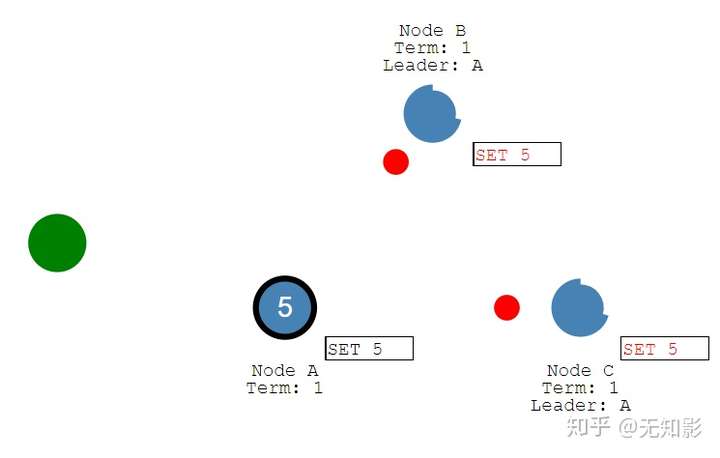
- 若集群中出现网络异常,导致集群被分割,将出现多个Leader
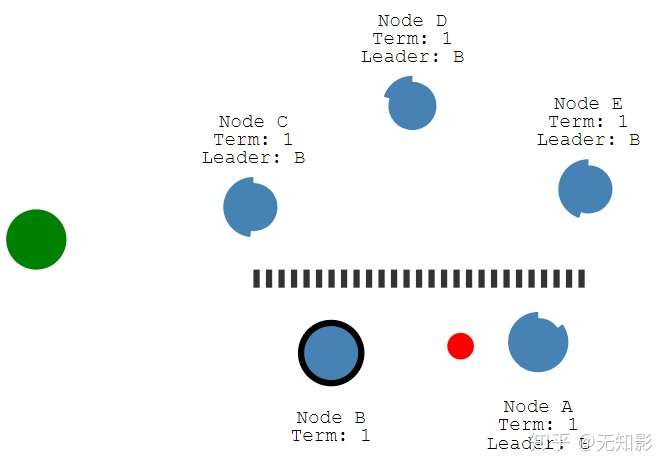
- 被分割出的非多数派集群将无法达到共识,即脑裂,如图中的A、B节点将无法确认提案。而多数派集群如C、D、E可以更新任期Term并正常工作。
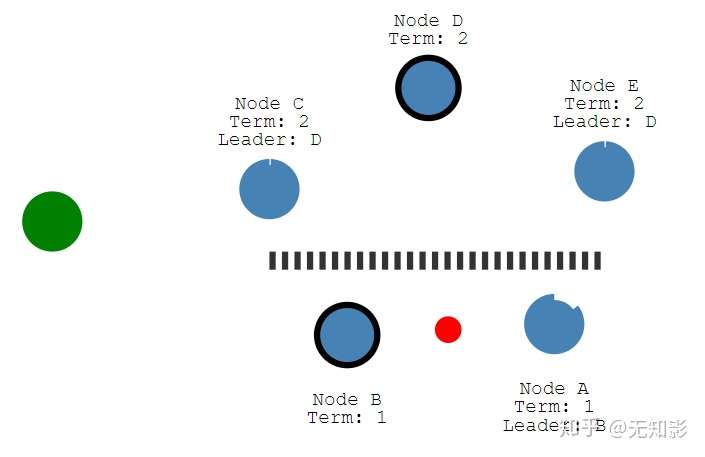
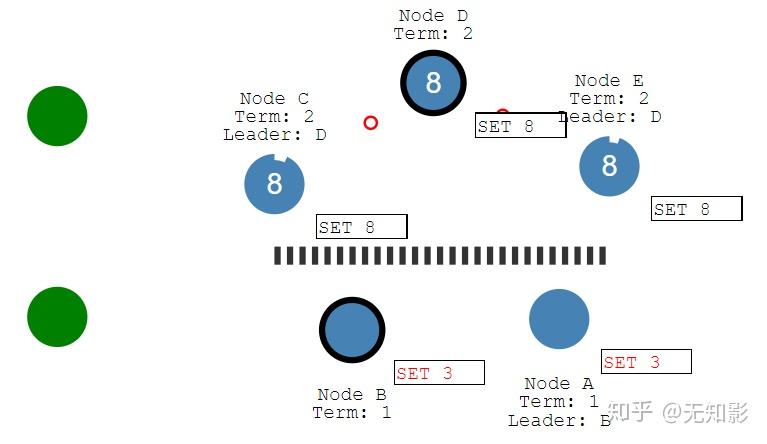
- 当集群再次连通时,将只听从最新任期Leader的指挥,旧Leader将退化为Follower,如图中B节点的Leader(任期1)需要听从D节点的Leader(任期2)的指挥,此时集群重新达到一致性状态。
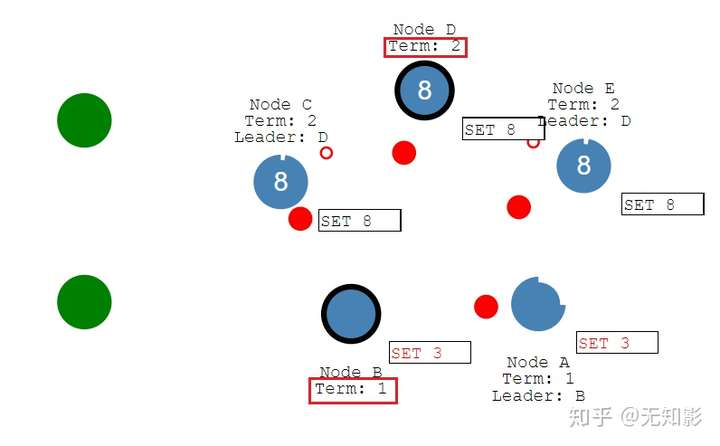
- 除此之外,节点 A 和 B 都将回滚其未提交的条目并匹配新领导者的日志。
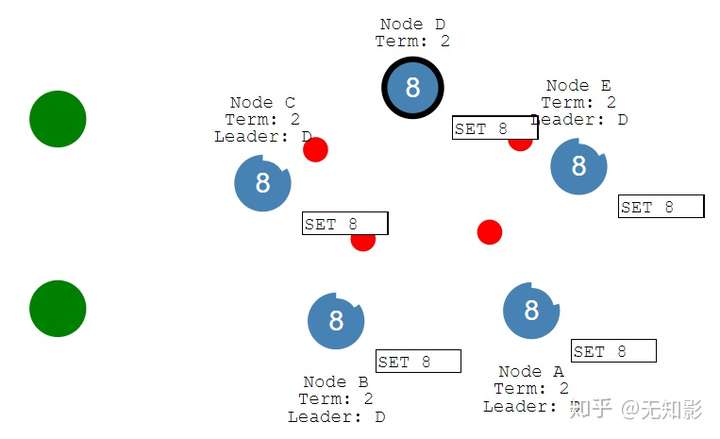
- 最终我们的说有节点数据满足最终一致性。
参考:



