
机器学习模型评价指标
机器学习模型评价指标
混淆矩阵
| 实际\预测 | 正样本 | 负样本 |
|---|---|---|
| 正样本 | True Positive (TP) | False Negative(FN) |
| 负样本 | False Positive(FP) | True Negative(TN) |
- true/false : 预测对否
- Positive/Negative:样本正负情况
- 如:True Positive 猜对了,是正样本。True Negative 猜对了,是负样本。
- 对一个系统来说,若TP增加,则FP也增加。
对于混淆矩阵,我们有四个度量标准
准确度(Accuracy) = (TP+TN) / (TP+TN+FN+TN)
猜对的次数占总的比例,适用: binary, multi-class
精度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)
猜对正样本的占预正样本的比例,适用:二分类模型
召回(recall, 或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate) = TP / (TP + FN)
猜对正样本的占实际正样本的比例,适用:二分类模型
特异度(specificity,或者真阴性率,TNR,True Negative Rate) = TN / (TN + FP)
猜对负样本的占实际负样本的比例,与召回率相反。
F1-值(F1-score) = 2*TP / (2*TP+FP+FN)
F1值是精确率和召回率的调和均值,适用:分类模型
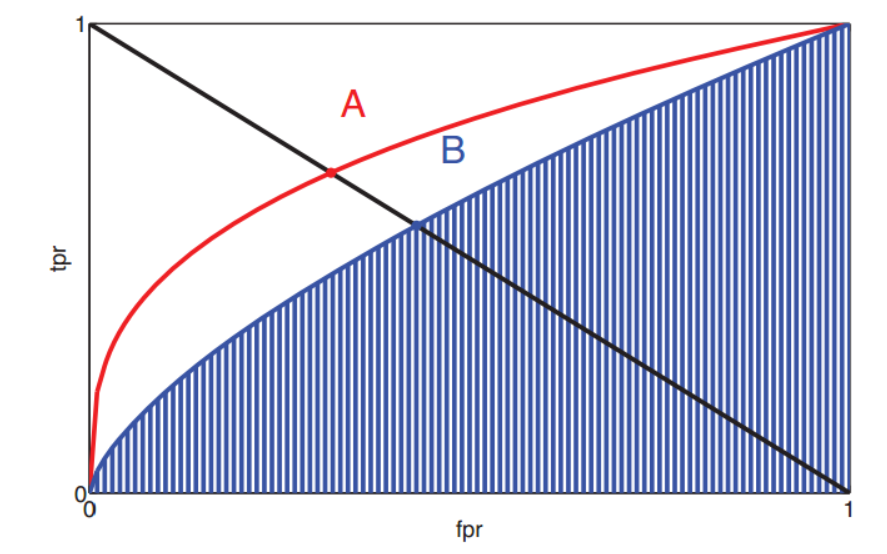
ROC曲线
通过对分类器阈值的调整,得到不同的TP和FP,以TP为纵坐标,FP为横坐标,构成的曲线就是ROC曲线。

同样的FP下,TP越大越好。最好不让FP发生。
理想中的ROC曲线应该是平滑的, 因为通过降低阈值 错误率也应该是随之上升. 如果不够平滑, 有可能是发生了overfitting或者是样本不足.
根据实际应用对曲线进行抉择。
FP越小,越安全,TP越大,越容易得到结果。
AUC曲线
将ROC曲线与X轴围成的面积作为一个指标,同样的FP下,面积越大的更优。但是只能用于二分类模型的评价。
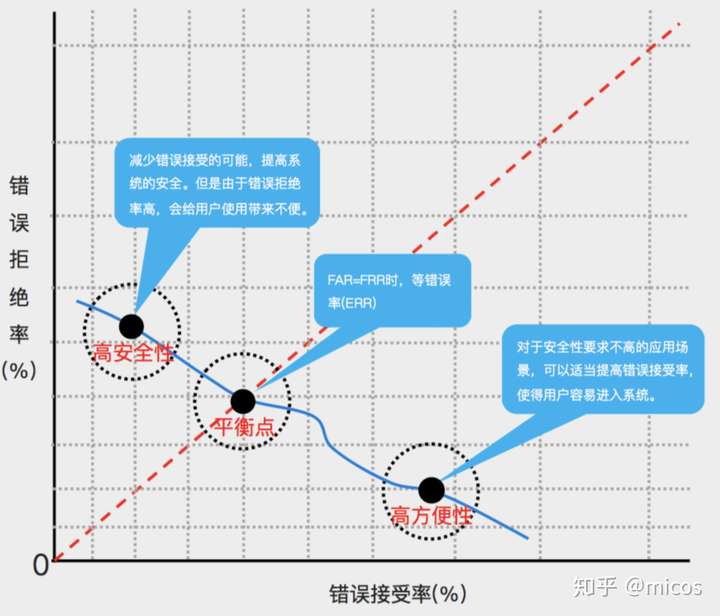
EER等错误率
两类错误FP和FN相等的时候的错误率,可以直观表现系统的性能。
直观表现就是从左上角TP=1做对角线到右下角FP=1,中间交ROC曲线的点。
等错误率越小,说明系统性能越好。
不同问题有不同的评价指标
分类
精确率、召回率、准确率、F值、ROC-AUC 、混淆矩阵、PRC
回归
RMSE(平方根误差)
MAE(平均绝对误差)
MSE(平均平方误差)
聚类
兰德指数
互信息
轮廓系数




