
CNN卷积神经网络
CNN卷积神经网络
深度学习其实源于多层神经网络,最近几年的飞速发展让其逐渐演变出自己的特点。
以CNN卷积神经网络为代表。
常用数据集
自编码器
部分解决部分神经网络参数初始化的问题。
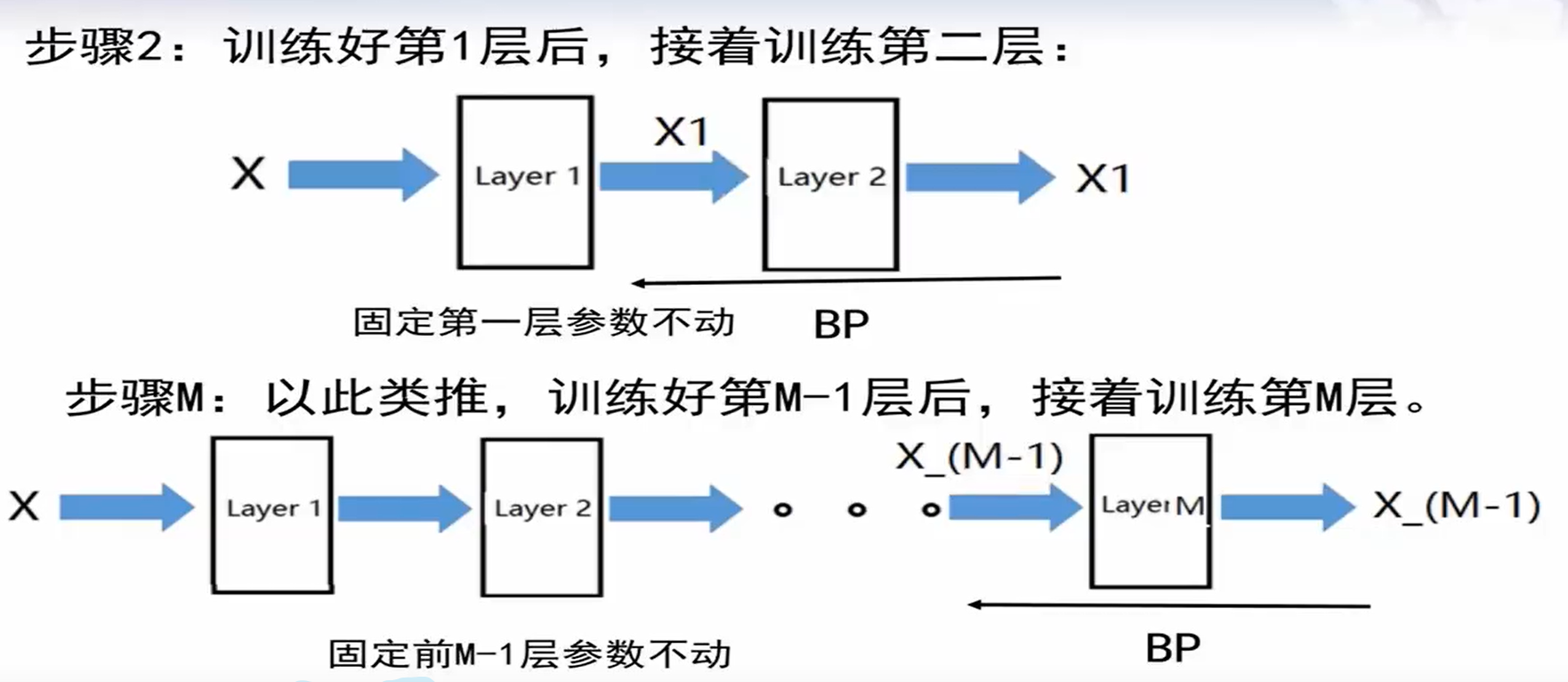
输入X,第一层的输出也为X,由此算出第一层的参数W,b。往后固定第一层参数不变,第二层输入为X1,假设第二层输出为X1,由此算出第二层的参数W,b。以此类推,求出每一层的参数。这样子算出来的参数保留了输入的特征,相当于是对特征在每一层进行特征压缩。
卷积神经网络CNN
由手工设计卷积核,到自动设计卷积核。
做各种变换时,本质是找一个卷积核对图像乘起来再加起来。
卷积神经网络中“卷积”,是为了提取图像的特征,其实只借鉴了“加权求和”的特点
CNN框架整体架构
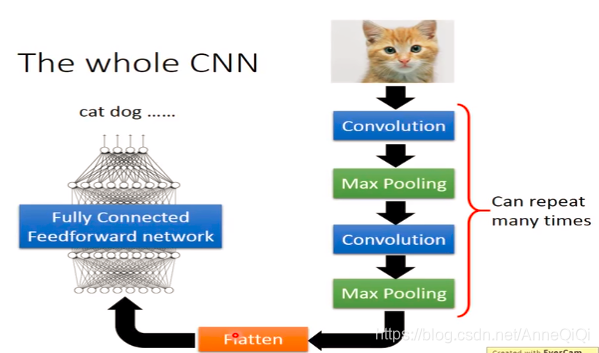
大体包含两个部分,卷积层和全连接层。全连接层就是原来普通的多层神经网络,但是卷积层包含两个部分的嵌套(卷积、池化)。卷积是对元数据进行加权求和,池化是对卷积的结果进行特征选择,降低特征数量,并从而减少参数数量。
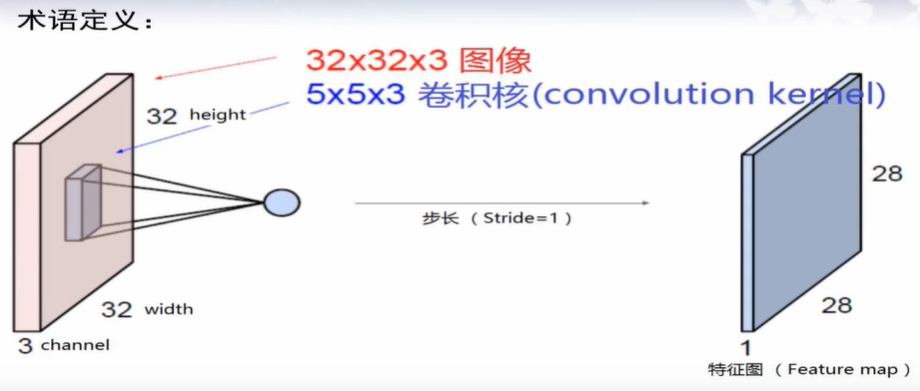
卷积核
通过设置一个卷积核区域,通常比输入空间小。

通过移动卷积核的位置,与特征空间对应的位置进行加权求和,得到一个压缩后的特征图。
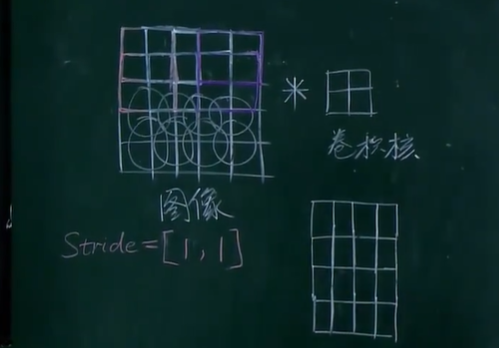
如一个5x5的特征矩阵,若使用2x2大小的卷积核,并且设置步长为[1,1],会产生一个4x4的特征图。

同理若是设置步长为[2,2],会产生一个2x2的特征图,但是会产生边缘部分未处理的问题。
对于边界问题,我们可以采取补0(zero-padding)的做法,产生更大的特征图。
总结其效果如下:
共享权重
有了如上,我们知道卷积核是如何工作,下面我们需要与多重神经网络做类比,其本质是什么。
上面的卷积操作,等价于如下的权值共享网络。
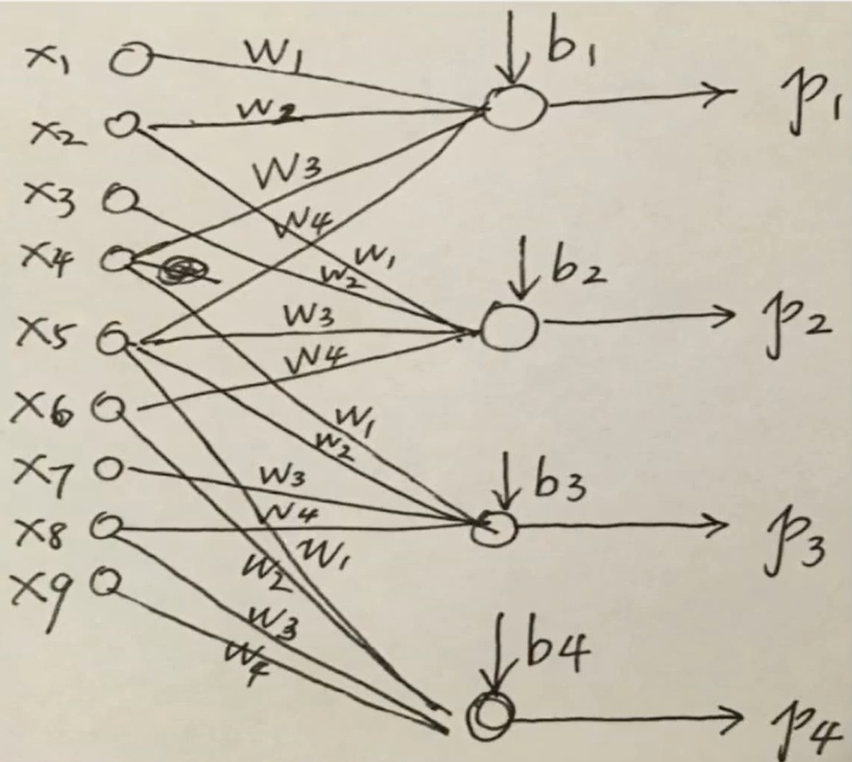
可以发现,此神经网络中某些输入是没有连接到所有的神经元上的,相当于其部分权重为0。(局部连接)
卷积层中每个神经元的共享权重W。其W的个数,取决于卷积核大大小,因为每个神经元(特征图中的一个结果)都是由同一个卷积核计算得到的。卷积核在这里充当了一个参数块的作用。
池化(二次特征选择)
池化层(pooling layer)也叫做子采样层(subsampling layer),其作用是进行特征选择,降低特征数量,并从而减少参数数量。
为什么conv-layer之后需要加pooling_layer?
卷积层【局部连接和权重共享】虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,很容易过拟合。为了解决这个问题,可以再卷积层之后加上一个pooling layer,从而降低特征维数,避免过拟合。
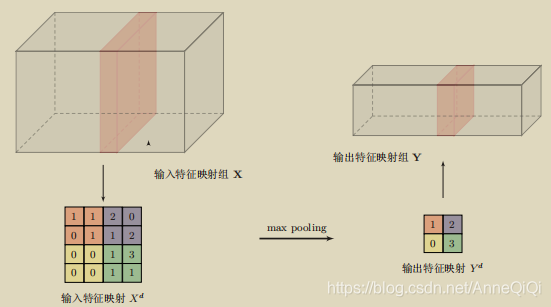
Pooling是指对每个区域进行下采样(Down Sampling)得到一个子特征图,作为这个区域的概括。常用的pooling 函数有两种:
1)最大池化(Max Pooling):一般是取一个区域内所有神经元的最大值。
2)平均池化(Mean Pooling):一般是取区域内所有神经元的平均值。
具体流程
以 LeNet-5处理手写数字图片为例。
- 卷积层:第一层选用6个5x5x1的卷积核,步长为1,去处理32x32x1的图像,得到28x28x6的特征图(注意每次卷积后,都需要经过激活函数,将结果非线性化处理)
- 卷积层:第二层(池化层)对28x28x6的特征图,使用2x2映射到1一个点,得到一个14x14x6的子选样特征图。(反向传播时,将该点的参数,映射回上一层的4个点即可。)我们也称这一个映射后的点的感受野是4。
- 卷积层:第三层选用16个5x5x6的卷积核,步长为1,去处理14x14x6的图像,得到10x10x16的特征图
- 卷积层:第四层(池化层)对10x10x16的特征图,使用2x2映射到1一个点,得到一个5x5x16的子选样特征图。
- 全连接层:后续操作就和普通的多层神经网络一样了,只是分类问题的目标函数,我们通常不用均方误差函数。而是使用softmax函数和交叉熵。

可以发现,整个网络的速度取决于卷积层,整个网络的参数个数取决于全连接层。
AlexNet的改进
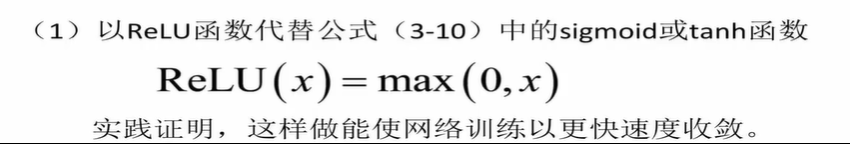
(2)使用Max pooling代替mean pooling。


(5)选用最新的GPU进行计算
VGGNet的改进
将池化层进行叠加,多个池化层进行叠加,导致池化层的结果感受野更大。
GoogleNet的改进
对channel进行加权,将一堆卷积核大小为(1x1x上一层输出的channel)、(3x3)、(5x5)的Inception(小卷积核)结构来代替大的卷积核。达到增加感受野、减少参数的效果。
ResNet残差网络的改进
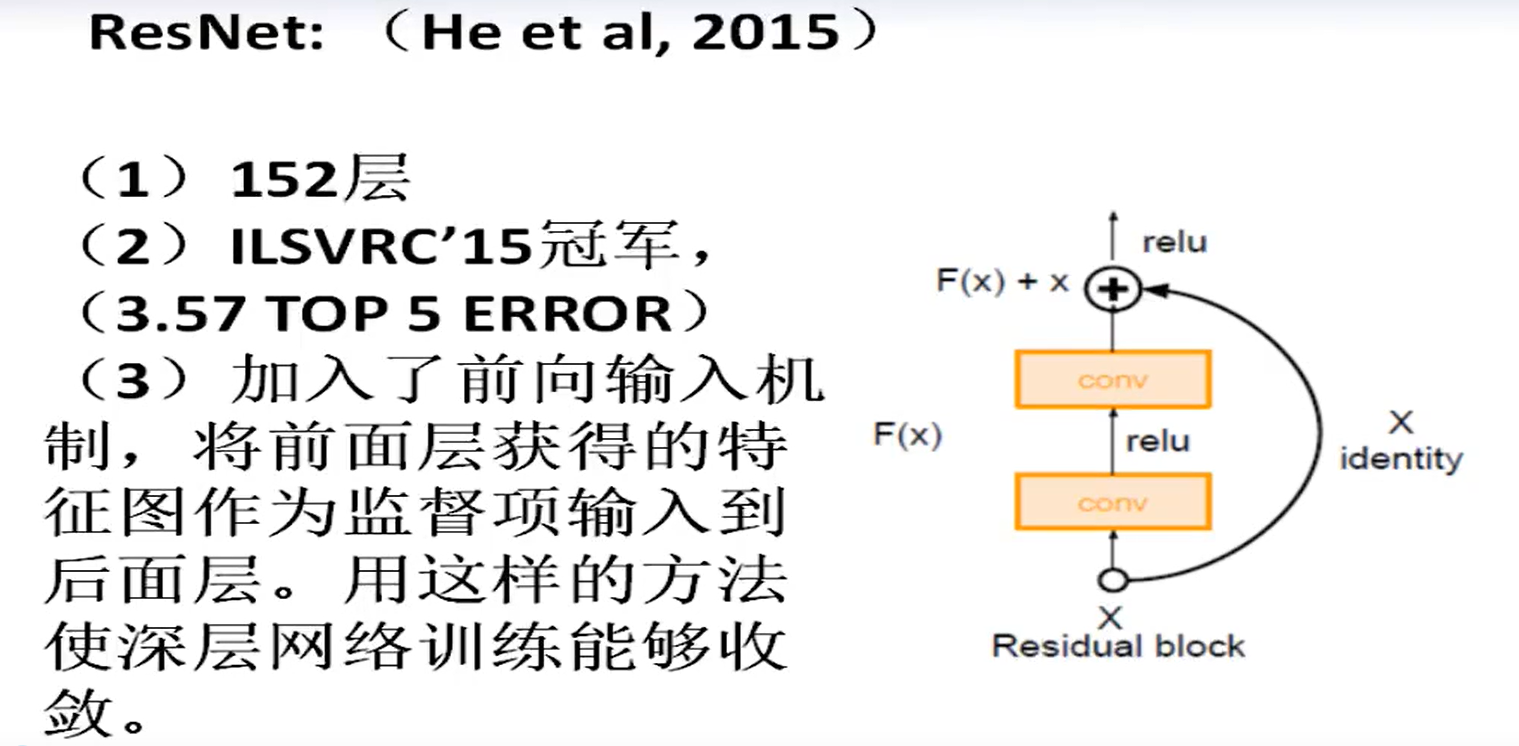
将前面层的结果直接加到后面层,经试验表明,效果会更好。




